WN9 Description
This page is a functional description of WN9 and the design process. If you're looking for information on how to implement WN9 on a website or service, see the WN9 Implementation page.
Contents
Goals
WN9 is an evolution of WN8 with similar principles:
- It should be similarly difficult to attain the same WN9 value in any tank, played with a decent crew and with all modules unlocked.
- WN9 should track solo tank-adjusted winrate as well as possible. The advantage of playstyles that do not increase solo winrate should be minimised.
- WN9 should be linear with contribution to give a better indication of the relative value of players.
These principles are not absolute and were traded against complexity of implementation. They're not generally controversial, although they are arguable on details. For example, winrate rates the value of top-tier performance more highly than most players would.
Summary of improvements
Improved expected values
WN8 used a single expected value per parameter. This doesn't work well because some tanks (typically lights and mediums) scale more rapidly with skill than others. WN9 adds a per-tank skill scaling value, which is equivalent to a two-point system and fits the evidence well.
The WN9 expected values are also generated using recent data, rather than WN8's overall data with a pseudo-recency filter. This fixes problems introduced by historical data and bias caused by tanks being played earlier in careers. It also allows removal of stock grind data and some crew-skill adjustment.
Separation of winrate-correlation from tank expected values
Instead of using a full set of expected values for each tank and each parameter, WN9 uses a single set per tier. Per-tank adjustments are still used, but only after the win-correlated formula. The principle (for what it's worth) is that the value of a point of damage, frag or spot towards winning the game is the same regardless of which tank you're driving.
The practical differences are small for most tanks, but there are significant effects on the two problem classes: Scouts and arty. For scouts, spots and frags are naturally better rewarded, while damage-padding is less rewarded. For arty, the big random chunk of WN8 provided by spots vanishes.
Linearised formula
The WN8 formula was generated by automatically fitting the other parameters to winrate. The main flaw with this method is that the input data included heavily-platooned players, and so the formula tracked platooned winrate rather than solo winrate. This led to huge numerical differences at the top end, which had little relationship to solo results.
With heavily-platooned players filtered out, contribution stats such as damage and frags were close to linear with winrate. The WN9 formula maintains that relationship: A player with twice the WN9 will be contributing roughly twice as much materially to their games.
Step 1: Tier adjustment
The first step simply divides the tank damage, frags, spots and defence by their tier average. Tanks with scout matchmaking use the averages for a tier higher, as that's roughly what they're fighting. The main effect is to reduce the relative importance of each point of damage for scouts. 100 damage contributes less towards winning tier 10 battles than tier 9 battles.
Note that it's possible to effectively implement different formulas based on tier or class by varying the divisors. For example, if frags are relatively important in the mid tiers, you can drop the expected frags value for mid tiers. However, tier averages were logical (for tanks with similar matchmaking) and there was little contradictory evidence in the practical results. There is also an argument for using slightly higher damage values for tanks with preferential MM, but the difference here is too small to be worth the complexity. Small differences here are easily fixed in the tank adjustment stage.
EU tier averages were used, but other servers had similar tier-relative performance so this wouldn't affect the results. It's unlikely that these averages would change substantially unless WG heavily rebalanced tank hitpoints across tiers.
WN8 users may recognise this step, but it's deceptive. In WN9, this stage only generates tier-relative performance indicators and doesn't adjust for individual tanks. Per-tank adjustment only happens after the formula step.
Step 2: Formula
The formula step attempts to correlate the tier-relative results from Step 1 with tier-relative winrate for various classes. The WN9 formula was created after substantial testing with a custom multiple linear regression solver. To avoid repeating WN8's primary mistake, platoon-padded players were filtered out using a model based on Top Gun, BIA and CC medals. Each component was automatically pre-linearised to avoid tracking the slight non-linearity in contribution vs winrate.
Separate correlation tests were run on various tiers and classes, with the following highlights:
- Damage dominates frags at tier 10, but frags and damage have roughly equal importance at tier 6. This is probably because winrate rates top-tier performance (high frags/damage ratio) as more important than bottom-tier performance (low frags/damage ratio).
- Cap points have a moderate influence at high tiers and for scouts, although not for mid tiers. WN9 did not eventually include cap points, but it does suggest that the pathological fear of the cap circle you see in high tier games is counter-productive.
- Defense points have a similar influence to cap points, but with less tier variation. Frags*defence is generally preferred to plain defence.
- Parameter caps (like WN8's rDmg+0.1) are generally counterproductive as long as the components are pre-linearised.
- Scouts really like frags*spots, and to a lesser degree dmg*spots. The correlation is actually quite good since recent map changes (R2 ~=0.83), not far below mediums. Mediums also like frags*spots more than heavies do, but the difference isn't huge.
- Artillery just wants damage & frags, nothing else. The correlation is pretty bad, probably because of a large proportion of pre-8.6 data, and a further performance dive since the personal missions started. Arty are hard-matched against other arty, which drags their winrates towards 50% regardless of current capability. Hence the damage vs winrate relationship for arty depends heavily on when you played it.
Metric formulas are not magical. You can mix and match various components and the correlation doesn't change much as long as they're roughly linearised. There are also reasons to prefer a formula that currently has an inferior overall correlation:
- Damage is far more accurate than other parameters over short runs. This is important for per-tank and per-battle stats.
- Trivially-paddable parameters should be avoided, especially if they may harm the game. Obvious examples are cap points and survival rate (which is generally negative anyway), and it's another reason to lessen the use of frags.
- The formula may be more accurate for players who care about the result. Hence the formula may prioritise accuracy for high tiers and medium tanks at the expense of mid tiers and artillery.
Based on the correlation data and the points above, the following WN9 formula was chosen:
wn9base = 0.7*rDmg + 0.25*sqrt(rFrag*rSpot) + 0.05*sqrt(rFrag*rDef)
Single battle formulas (as used by in-game mods) shouldn't have parameter multiplications in them because they make the result too noisy. WN9 instead uses the following formula for single battles and other low battle count cases:
wn9base = 0.7*rDmg + 0.14*rFrag + 0.13*sqrt(rSpotC) + 0.03*sqrt(rDef)
Step 3: Per-tank adjustment
Finally, the result of the formula step is adjusted using the per-tank WN9 expected value and scale to give a tank-independent "skill". The method of generating these values is explained in detail on the Expected Values Method page, so here are the details specific to WN9:
- The input data is 10 weekly diffs of 300k high-activity EU players, with rare tanks blended from RU and the previous EU sample.
- Expected values are provided for all tanks with known IDs. In cases with insufficient data, values were taken from similar tanks or historical sources.
- Data was almost all random battles, with a trace quantity of Company battles.
- The wn9base formula was used directly to generate the inputs.
Nerf adjustment
The WN9 expected value and scale work best for recently-played tanks, as they're based purely on recent data. Some WN9 metrics also make use of maximum historical tank capability, or pre-nerf performance. This is handled with per-tank multipliers to the expected value.
The nerf modifiers were generated by comparing extrapolated high-skill expected values with real top performances, on the basis that they should correlate for tanks with a similar player population, except in cases where tanks were significantly stronger in the past. These results were sanity-checked against historical patch notes.
Nerf modifiers were only generated for the expected values, not the scales. The assumption is that the character of tanks didn't significantly change when they were nerfed. In some cases this may not be strictly true (Hellcat, VK36), but the difference isn't likely to be significant.
Metric variations
Per-tank WN9
This is the simplest WN9 metric. It uses per-tank random battle data to generate a WN9 value per tank, which can be used for comparing performances in different tanks, or combined to generate tier/class WN9 values. The same method is used for generating WN9 results for single battles.
Because there's often no way of determining when a tank was played, sites may want to generate two WN9 values per tank: As if the tank was played recently (unmodified) and as if the tank was played at its maximum historical capability. In the latter case, the nerf adjustment is applied to the tank's expected value.
Recent WN9
Recent WN9 is designed to use the same input data as recent WN8: Overall dmg/frag/spots/def, plus a battle count per tank played over the interval. It's more complex than the WN8 version because the exp and scale values need weighting, but otherwise the principle is similar.
The weights for the expected values are calculated from the tier averages and the WN9 formula. Similarly to WN8, higher tier tanks have a greater weight in the formula due to raw damage output increasing with tier, and the expected values need to have a similar weight. The scale values are also weighted by the expected values, because that's what they're defined relative to.
The low battle count formula is not used, because the method isn't intended for small battle counts. No nerf adjustments are used, because it's supposed to be used with recent data. While the same formula can generate an "overall WN9", this should only be used for testing. The recent WN9 method handles missing tanks by dividing the average performance by the average expected value. There may be a bias, depending on the expected values of the missing tanks, although in most cases the result should be fairly close.
Sites that collect full per-tank dmg/frag/spots/def interval data can instead implement recent WN9 by battle-weighting per-tank WN9 results over the interval. This will give slightly different results from the standard method, but intervals vary between sites anyway. This method should be slightly more accurate as long as the low battle count formula isn't required for too many per-tank results.
Account WN9
Account WN9 is a replacement for overall WN8 that throws away each player's worst tanks. The goal is to reduce reroll incentive, work around problems with historical nerfs & buffs, and make it work better as a skill metric for applications where you can't use recent WN9.
The discard level is currently set at 65% of battles (selected by tank), which was chosen by polling. These are the effects of using lower percentages:
- Less reroll advantage / incentive.
- More tolerant of stock grinds & play for fun tanks.
- Less like an overall metric.
- Players who only play well in some tanks will be rated more highly.
- Stagnant-skill accounts are more likely to have account WN9 > recent WN9.
Artillery are not included in account WN9 because their data has severe historical and meta problems: Even for SPGs introduced after 8.6, meta differences over time and between servers are substantial. Artillery skill also doesn't correlate as well with skill in other tanks.
Account WN9 also has a weight cap per tank, currently set at tanktier*(40 + tanktier * total battles /2000). This exists partly because there's a practical advantage to playing fewer tanks (crew skills, credits, stock grinds) and also because it makes sense to reward exploring the game in an achievement metric. The weight cap was chosen based on a number of factors:
- The actual penalty for playing additional tanks, given decent crew management and moderate spending.
- Real data on how players accumulate battles at various experience levels.
- Enabling players with a large number of tanks unlocked to improve their account WN9 at a reasonable rate without dropping back to lower tiers or playing horrible tanks.
- Enabling f2p players to progress at a decent rate.
Historical nerfs are handled by halving the weight (and weight cap) of tanks that were nerfed, so playing an overpowered tank has a limited impact on your account WN9 after it's nerfed. Players who play a tank which is then buffed will be punished somewhat, but the capping system does give them an opportunity to correct it.
Testing
To test how well various metrics track solo tank-adjusted winrate, the following method was used:
- Throw away accounts with significant platoon-padding.
- Calculate the result of each metric for each account.
- Place the results in bins split by tank-adjusted winrate.
- Calculate the standard deviation of the results in each bin.
- Scale the results for each metrics so that they're roughly comparable.
Lower standard deviations mean that the players with similar "skill" have less numerical variation in that metric. Tank-adjusted winrate is used for "skill", because it's probably the best account metric for solo players. When scaling the metrics, the zero points were left alone, so to get an idea of relative error you need two graphs:
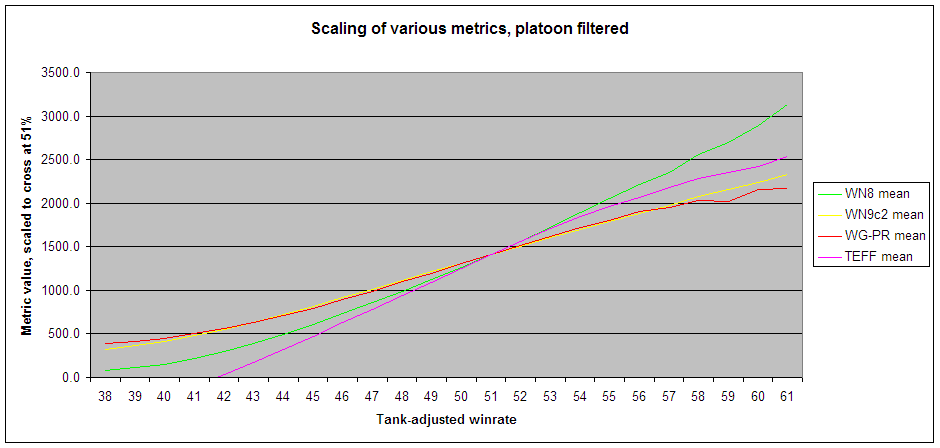
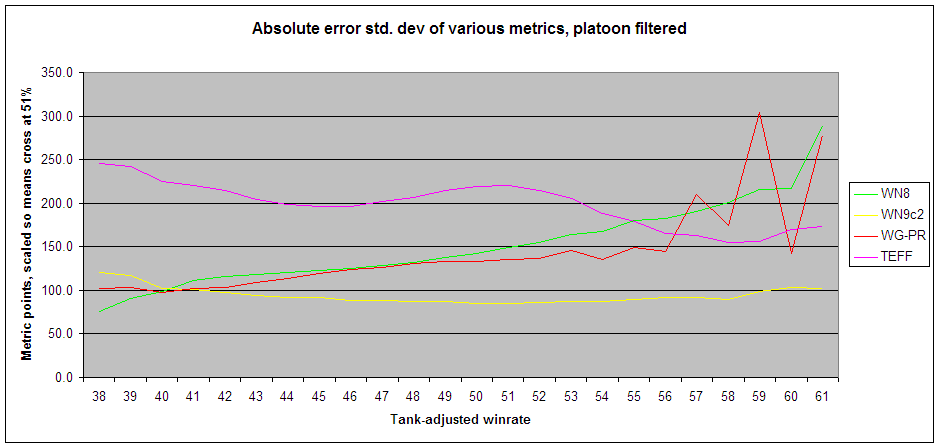
Notes:
- Battle-weighted (tanks/stats based) overall WN8 and WN9 were used. The standard overall/recent WN8 & recent WN9 methods can be slightly less accurate due to cross-tier normalization issues. WG-PR and xTE don't have recent methods.
- WN8 and especially WG-PR should gain an advantage here from using winrate in their formulas (and proxies such as survival rate and base XP), at the expense of accuracy in platoon-padding cases. The vast majority of high-skill players are somewhat platoon-padded.
- Using rWin (WN8 component) instead of tank-adjusted winrate made little difference to the relative position of the metrics, although it helped WN8 slightly at the middle of the skill range. All errors increased with rWin, because it's an inferior metric.
- The zero points for different metrics are not equivalent. WN9 uses zero-means-zero to retain linearity for player comparisons. WN8 uses something like zero-means-average-bot, while the xTE zero is even higher.
- It wasn't possible to get accurate top-end values for WG-PR because you can't calculate it for a subset of an account.
Observations:
- WN8 is an increasingly poor metric with increasing skill, as expected. On absolute error it cheats at the low end, because the non-linear terms and zero-point caps drag the bad players closer together.
- TEFF is terrible in the middle, but better than WN8 at the top end, as expected.
- WG-PR runs pretty close to WN8 on relative error, except at the low end where it's the single best metric. This is probably because the bottom of the graph is heavily populated with deep campers, and so access to spotting damage and direct use of winrate are big advantages.
- WN9 tracks solo tank-adjusted winrate far better than the other metrics, especially at higher skill levels
Per-tank and recent metric error
Because most players play many different tanks, per-tank error will be much higher than overall error in WN8 (especially for good players) and xTE (for mediocre players). Recent WN9 should perform even better relative to WN8 recent metrics, because it's based purely on recent data.